Apache Druid Software Pricing, Features & Reviews
What is Apache Druid?
Apache Druid is a high-performance, open-source analytics database designed to handle large volumes of both streaming and batch data with sub-second query responses.
It uses a distributed architecture with specialized nodes for ingestion, storage, and querying, making it scalable from a single server to massive clusters.
Data is stored in a column-oriented, time-indexed format, allowing efficient filtering, aggregations, and interactive analytics even on billions of rows.
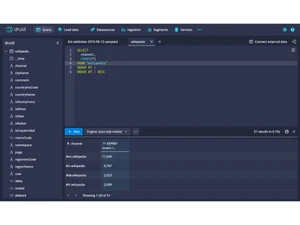
Druid can ingest data in real time from streams like Kafka or Kinesis, as well as in batches, making it instantly queryable. It supports standard SQL, enabling developers and analysts to run familiar queries for dashboards and analytics.
The platform handles high-concurrency workloads efficiently with parallel processing and optimized indexing. Common use cases include clickstream analytics, IoT and event data analysis, real-time monitoring, marketing analytics, and powering BI dashboards.
Why Choose Apache Druid Software?
- Sub-Second Queries: Delivers extremely fast query responses even on massive datasets.
- Real-Time Ingestion: Can ingest streaming data from sources like Kafka or Kinesis and make it instantly queryable.
- Batch & Stream Data Support: Handles both historical (batch) data and live (streaming) data together.
- Scalable Distributed System: Scales easily from a single server to clusters with hundreds of nodes.
- Columnar Storage: Uses column-oriented storage so queries only touch needed data, making analytics faster.
- Massively Parallel Processing: Executes queries in parallel across the cluster for high performance.
- Time-Partitioned Storage: Partitions data by time (and optionally by other dimensions), which speeds up time-based queries.
- Optimized Data Format & Indexing: Uses compression, bitmap indexes, and dictionary encoding for efficient storage and fast filtering.
- High Concurrency: Supports hundreds to tens-of-thousands of queries per second without performance drop.
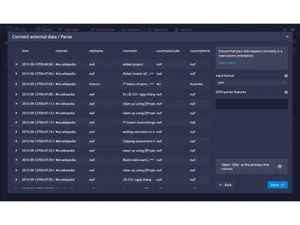
- Flexible Schema Handling: Accepts semi-structured or evolving data, reducing schema management burden.
- Interactive Query Engine: Designed for fast, ad-hoc slicing, dicing, filtering, and aggregations.
Benefits of Apache Druid Software
- True Real-Time Analytics: Great for live dashboards, monitoring, and immediate insight use-cases.
- Support for High-Cardinality & High-Dimensional Data: Efficiently handles data with many dimensions (tags, attributes) without slowdowns.
- Automatic Data Indexing & Compression: Reduces storage needs while enabling fast query performance.
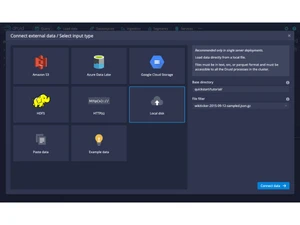
- Flexible Ingestion Sources: Accepts data from message buses, object stores, files, and multiple formats (JSON, Parquet, CSV, etc.).
- Self-Healing and Fault Tolerance: If a node fails, Druid can recover and keep serving queries without downtime.
- Deep Storage for Durability: Keeps a persistent copy of data in external storage, ensuring data safety and recoverability.
- Pre-Aggregation / Rollup Support: Optionally aggregate data at ingestion time to speed up queries and reduce storage.
- Approximate and Exact Aggregations: Offers both exact and approximate methods for fast metrics like unique counts and quantiles.
- Cost-Effective Infrastructure: Efficient storage and compute usage often costs less than traditional data warehouses.
- Suitable for Diverse Use Cases: Works for clickstream analytics, IoT, server logs, marketing data, BI dashboards, and more.
- Excellent for High-Frequency & Real-Time Data: Real-time ingestion plus fast queries equals live analytics for streams and events.
- Unified Platform for Streaming and Historical Data: No need for separate systems for real-time and batch analytics.
Apache Druid Pricing
Apache Druid is available for FREE as listed on Techjockey. The pricing model is based on different parameters, including extra features, deployment type, and the total number of users. For further queries related to the product, you can contact our product team and learn more about the pricing and offers.





 Realtime Ingestion
Realtime Ingestion